


بررسی تنوع ژنتیکی با استفاده از نشانگرهای مولکولی
یکی از پیامدهای اجتناب ناپذیر کشاورزی نوین که مبتنی بر استفاده از ارقام اصلاح شده با بیشترین عملکرد و کیفیت قابل قبول است، کاهش تنوع ذخایر ژنتیکی است. اگرچه تخمین کاهش تنوع ژنتیکی، مشکل و در برخی موارد غیر ممکن است، اما در اینکه بسیاری از ژن های مفید از دست رفته اند. ذخایر ژنتیک با سرعت فرآیندهای کاهش یافته اند. محصولات زراعی عمده در معرض تهدید روزافزون شرایط محیطی نامناسب و تنش های زیستی و غیر زیستی قرارگرفته اند، تردیدی نیست. بنابراین امروزه آگاهی از تنوع ژنتیکی و مدیریت منابع ژنتیک، اهمیت بسیاری دارد.
کاربرد بررسی تنوع ژنتیکی با استفاده از نشانگرهای مولکولی
۱- مطالعه تنوع حیاتی
۲- شناسایی رقم
۳- تجزیه فیلوژنتیکی، اکولوژی گیاهان
۴- تجزیه جمعیت پاتوژن
۵- می توان از فاصله ژنتیکی بین والدین، جهت پیشگویی عملکرد هیبریدها استفاده کرد.
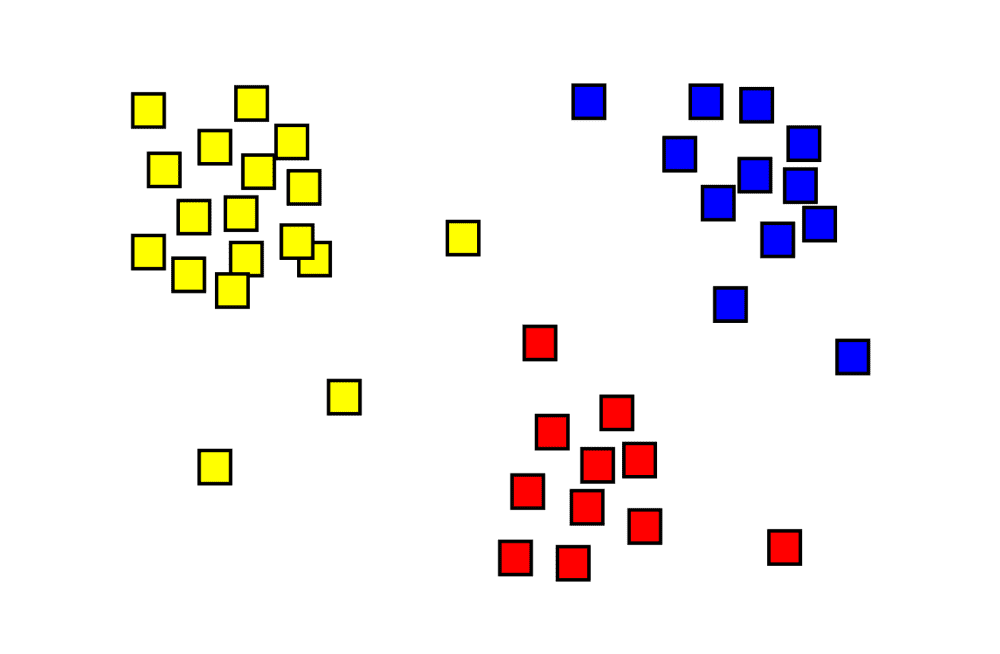
تجزیه و تحلیل تنوع ژنتیکی

یکی از بهترین راهکارهای طبقه بندی ذخایر توارثی و تجزیه و تحلیل تنوع ژنتیکی بین افراد، استفاده از الگوریتم های آماری چند متغیره است. در تکنیک های تجزیه و تحلیل چند متغیره از تجزیه هم زمان چندین متغیر برای بررسی روابط بین افراد استفاده می شود. این تکنیک ها امروزه به طور گسترده برای تجزیه و تحلیل تنوع ژنتیکی داده های مختلف از قبیل داده های مورفولوژیکی، بیوشیمیایی با نشانگرهای مولکولی مورد استفاده قرار می گیرند.
تجزیه خوشه ای
تجزیه خوشه ای یک روش آماری چند متغیره می باشد. هدف اولیه آن گروه بندی افرادی بر اساس میزان تشابه می باشد. به طوری که افراد مشابه از نظر صفات (نشانگرهای) مورد بررسی ما در یک خوشه واحد کنار هم قرار می گیرند. بنابراین در روش تجزیه خوشه ای، افرادی که در یک خوشه قرار دارند، در نمایش هندسی در کنار هم قرار می گیرند. افرادی که در خوشه های جدا قرار دارند، از هم دورتر خواهند بود.
روش آماری تجزیه خوشه ای
تجزیه خوشه ای با تشکیل ماتریس داده ها آغاز می شود. بسته به بارز یا هم بارز بودن نشانگرهای مورد استفاده نحوه نمره دهی باندها و ایجاد ماتریس داده ها می تواند متفاوت باشد. قبل از انجام تجزیه خوشه ای باید ماتریس تشابه براساس میزان تشابه دو به دوی بین ژنوتیپ ها یا نمونه های مورد بررسی تشکیل شود. بنابراین هرچه دو ژنوتیپ از نظر نشانگرهای مختلف الگوی مشابه تری با همدیگر داشته باشند، تشابه ژنتیکی آنها بیشتر خواهد بود و بالعکس.
منبع : کتاب نشانگرهای مولکولی، انتشارات دانشگاه تهران





دیدگاهتان را بنویسید